 Go:GMP模型深入理解
Go:GMP模型深入理解
# 一、基础知识学习
# 1.1 概述
计算机最早是时候是单进程时代,一次只能执行一个进程任务,其他进程想执行任务,只能等待排队。
后面出现了多进程、多线程,可以同时执行多个进程/线程任务,但是这个是并非真正的同时执行。而是将CPU的执行时间切分成一个个时间单位(时间片),然后将这些进程/线程切换着执行。
如果一个进程资源很大,那么这个进程的创建、销毁、切换都会占用很大的时间,切换时会有切换成本。

# 1.2 进程和线程
进程是资源分配的基本单位,线程是调度和执行的基本单位,一个进程下的多个线程共享内存资源,可以互相访问。但是多线程也存在着很多的问题:锁、资源竞争、同步。
# 1.3 内核态和用户态
这个知识点的概念我还是很模糊,只能结合几篇文章后来尝试表达我的理解。
首先内核态(Kernel Mode)和用户态的(User Mode)主要的区别是执行的权限的不同,用户态可执行的权限小,而内核态可以执行的权限大,这个权限范围是由 CPU 控制的决定的,内核态的权限指令集是 Ring 0,用户态的权限指令集是 Ring 3,执行某些操作用户态没有权限完成,那么就是需要去调用内核态来执行这个命令,我们通过系统调用提供的接口来调用我们的内核态。下图是 Linux 操作系统的架构图。
图中的几个概念理解:

用户态可以执行的权限操作特别少,像是线程的创建、销毁以及定时器等这些不调用底层硬件的操作命令。所以程序的如果要正常执行,那么需要一个用户态线程绑定一个内核态线程,对于内核态,CPU 无法感知它的存在,从 CPU 的视角出发,它只能感知内核态的线程。

它们都是线程,我们对它们进行的区分,用户态的线程叫作 协程(Co-routine),内核态的线程还是叫作 线程(Thread),线程由 CPU 负责调度,是抢占式的,也就是说一个线程不能允许一直被占用执行,最大允许时间是 10ms,超过时间就会被强制中断运行下一个线程,而协程是协作式的,由线程自己决定控制执行权。
# 1.4 线程和协程映射关系
- N:1 多个协程对应一个线程,但是如果有一个协程阻塞了,那么就是全部阻塞了;
- 1:1 一个协程对应一个线程,如果这种资源代价贵;
- M:N 多个协程对应多个线程,实现起来比较复杂;
# 1.5 goroutine
goroutine 是 Go 语言中协程的概念,它非常的轻量,而且可以弹性伸缩,支持 4KB ~ 2GB 的内存范围,同时如果有阻塞,通过 runtime 可以调度其他协程执行。
# 二、GMP 调度器模型
# 2.1 早期的 GM 模型
- G 表示 goroutine 协程
- M 表示 thread 内核态线程
所有待执行的 G 都存储在全局队列中,为保证资源竞争,会有一把互斥锁,每一次的创建、获取、销毁 G 都需要加锁。
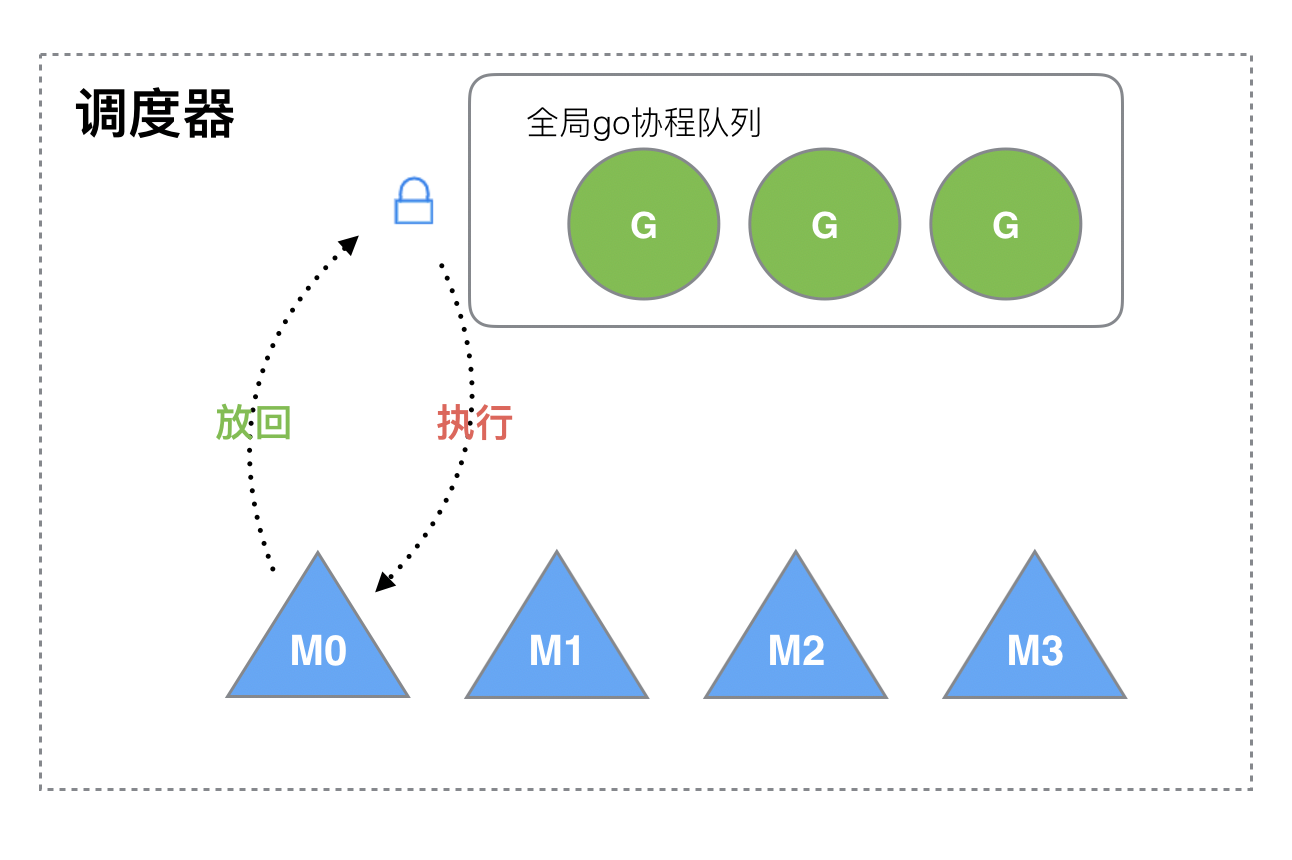
所以就会暴露出来几个问题:
- 全局一把锁,激烈的锁竞争,造成额外的资源浪费;
- 系统调度的额外开销,G 和 M 的频繁切换;
- 线程的局部性,G 创建的新线程 G2 会被随机的其他 M 执行,它们两个线程是相关的,最好应该在一个线程执行。
官方报告引述:
Vtocc (opens new window) server maxes out at 70% CPU on 8-core box, while profile shows 14% is spent in runtime.futex().
Vtocc 服务器在8核机器上的CPU使用率最高达70%,而分析显示有14%的时间花费在
runtime.futex()上。
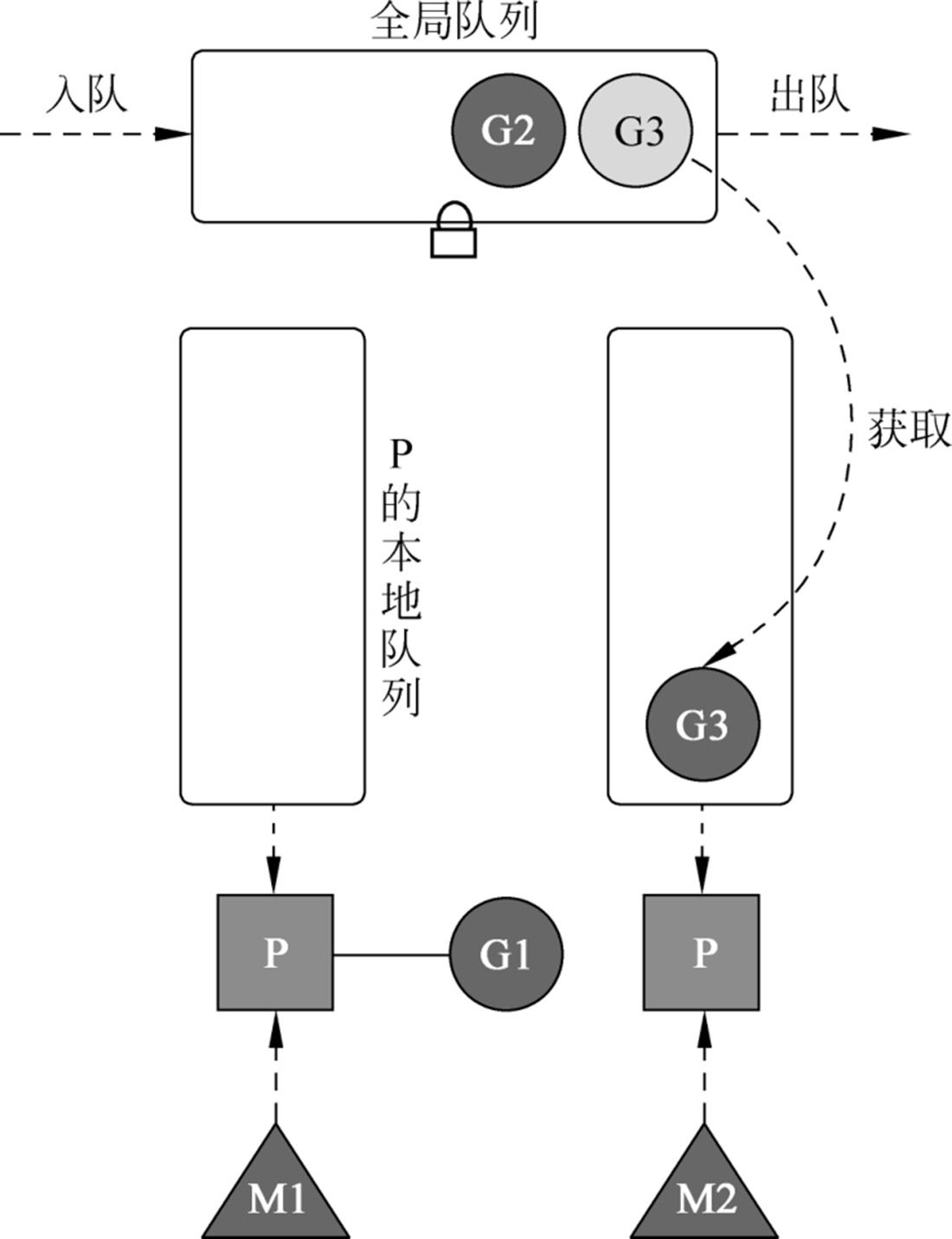
# 2.2 GMP 模型
现在的 GMP 模型如下图所示:

G groutine
4KB ~ 2GB
全局队列
存放等待运行的 G,因为是全局共享的资源,有互斥锁。
本地队列
和一个执行器 P 绑定,存放本地将要被执行(也是等待运行,状态码是
_Grunnable)的 G,有限制,不超过256个,底层是 P 的一个字段,数据类型是[256]guintptr;执行器 P
负责将绑定的本地队列交给绑定的 M 执行的执行器,也存在互斥锁,但是影响不大;
组成了一个执行器P列表,列表的执行器个数由 GOMAXPROCS 决定。
一个 P 和一个 M 绑定,从 本地队列去获取 G来执行,但是 P 和 M 之间的数量没有绝对关系,当 M 执行的阻塞了,它会切换或者创建一个 M 绑定执行后面的 G。
M 内核态线程
内核态的线程。在 M 空闲或者阻塞的时候,它不需要 P,在运行 M 时,它必须绑定一个 P。
M 和 M 相当于是有竞争的关系,M 的数量 >= P 的数量,M 会去争取绑定一个 P,如果没有空闲的 P,那么 M 就会休眠,最后会垃圾回收。
# 2.3 设计策略
# 1. 复用策略
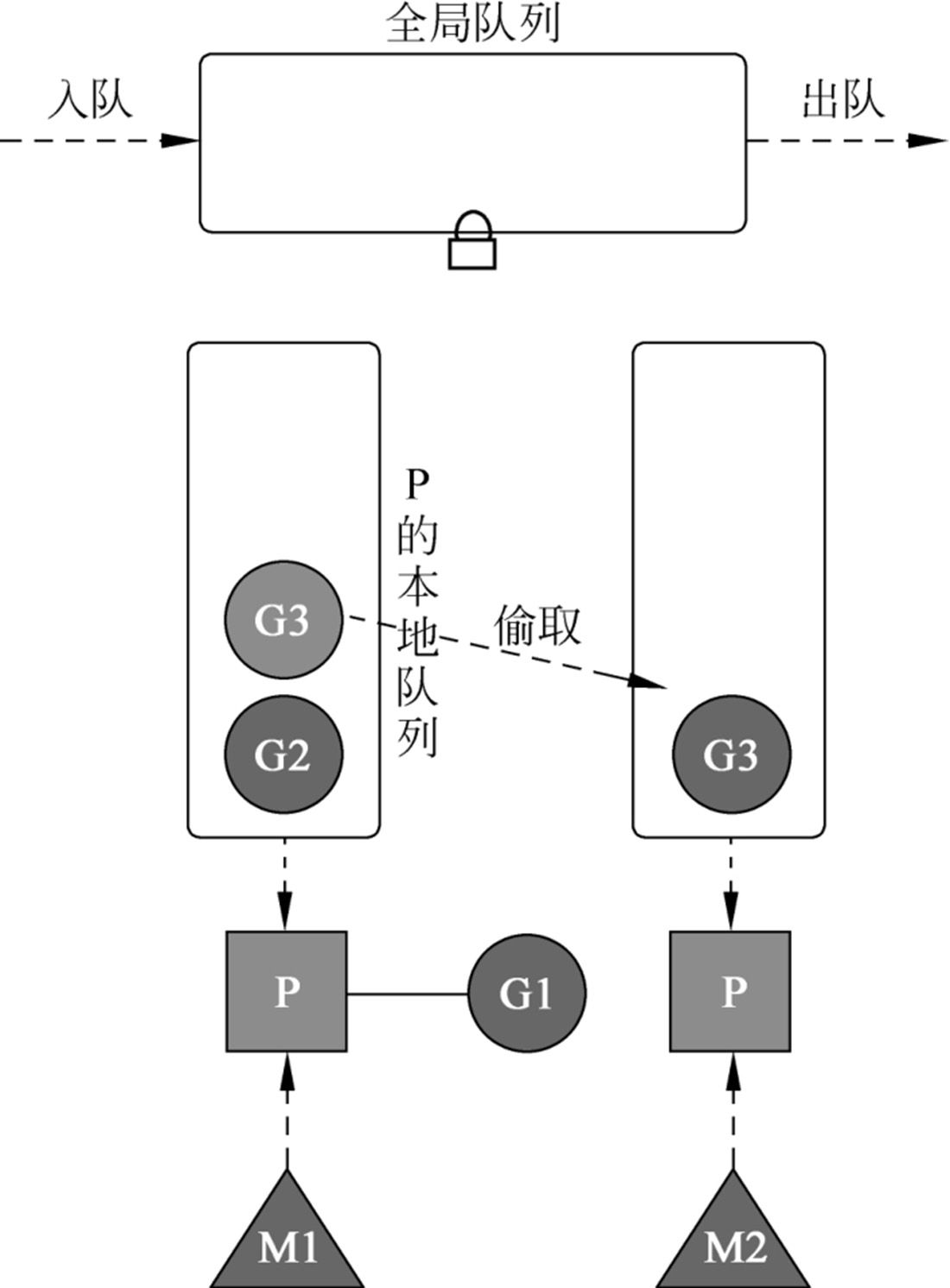
偷取机制(work stealing)
M 没有可以运行的 G ,P就去别的线程去获取可以执行的 G 来。
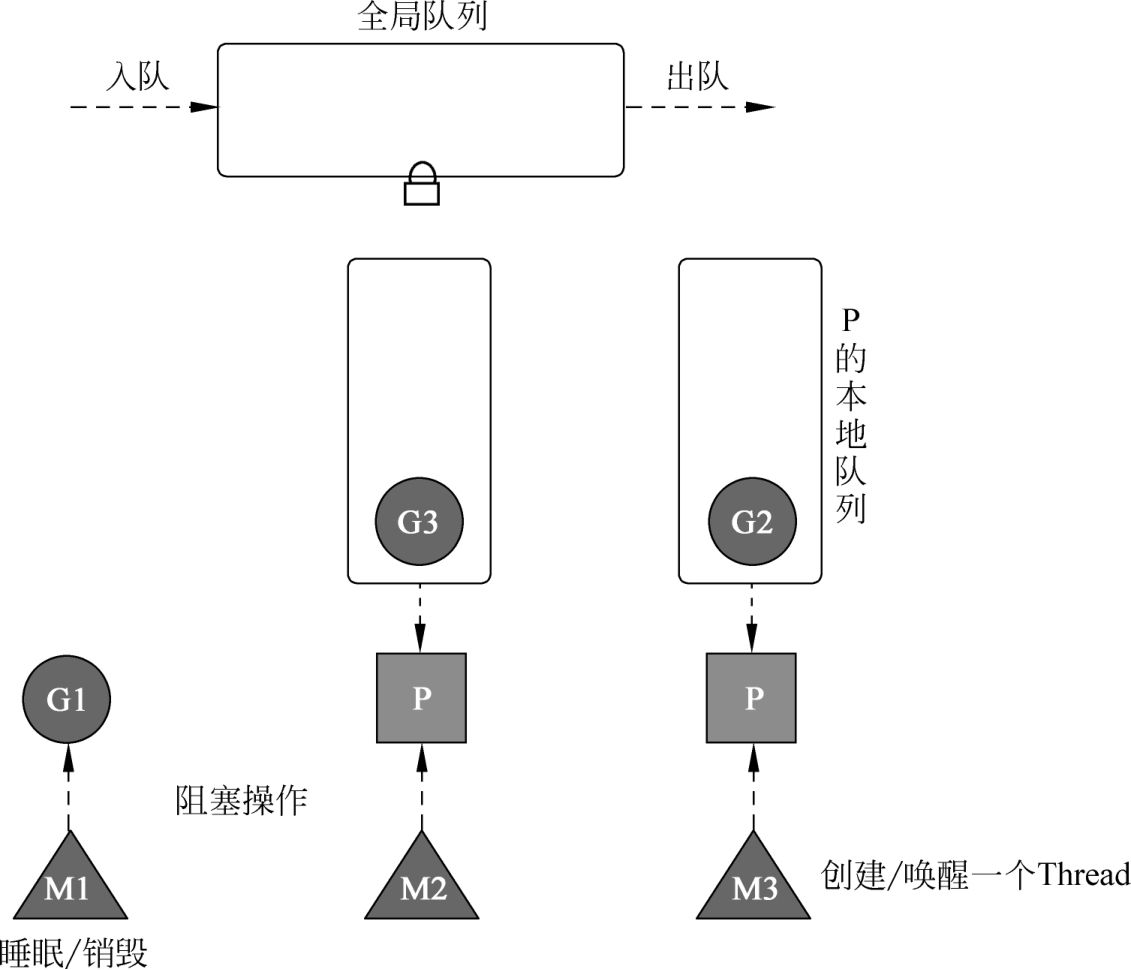
移交机制(Hand off)
当前 M 阻塞了,P和本地队列会重新绑定到空闲的线程上面去。
没有空闲的 M,就会去创建新的一个 M 然后绑定。
# 2. 利用并行
GOMAXPROCS 设置线程在多个 CPU 上同时运行。
# 3. 抢占
每个 G 每次最多只能占用 CPU 10ms时间,这个由 monitor g 来全局监控

# 4. 全局队列
前面提到的偷取机制,如果本地队列为空时,先去全局队列获取执行,全局没有,就去别的 P 的本地队列获取 G 来运行。
# 2.4 go func 执行流程
go关键字创建了一个新的goroutine;- 优先放入本地队列,如果本地队列满了,再放入全局队列;
- M 循环执行本地队列的 G;
- 如果本地队列为空,优先去全局队列取 G,全局队列是空的,那就去其他本地队列去取(working steal)。
- 如果运行中遇到了 M 的阻塞,那么 P 就去绑定空闲或者创建新的线程;
- 阻塞的 M 执行完 G 后,因为没有 P 没有和它绑定了,M 就休眠,G 放到全局队列。
# 2.5 生命周期
- 创建第一个线程 M0 和 G0,只负责初始化的一些操作,初始化之后,M0 变成普通的 M;
- 每个 M 都有一个 G0,不参与代码的执行,只负责调度以及垃圾回收;
- 初始化会创建预先设置好的 GOMAXPROCS 个 P,并且会绑定到 GOMAXPROCS 个 M 上面去;
- 初始化创建主 goroutine,就是 mian.mian 函数,然后执行;
- 一般情况下,main.main 在 M0 上面执行;
- 如果在 M 执行过程中遇到了系统调用,那么此时会阻塞,与之绑定的 P 会绑定到别的空闲的 M 或者创建新的 M;
- 当一个 G 被执行完,不会马上被销毁,而是会被放入到全局队列中,然后再等到调度器回收;
# 三、执行过程分析
# 3.1 G1 创建 G2
# 3.1.1 本队队列空间足够
G1 创建了 G0,此时本地队列有足够的空间,为了保证局部性,那么就直接将 G2 放入和 G1 一起的本地队列;
# 3.1.2 本地队列空间不足
每个本地队列最多只能存放 256 个 G,如果本地队列放不下了,那么就需要执行负载均衡,把本地队列的前一半 G,以及新创建的 G2 放入全局队列,如果 G2在当前 G 之后就执行,则用某个老 G 替换放到全局队列,放入全局队列的顺序是被打散的。
# 3.2 G0 调度
# 3.2.1 本地队列有空闲 G
G1 执行完毕或者执行 10ms之后,M执行的对象将切换为 G0,然后从绑定的 P 的本地队列获取下一个 G2,然后 G0 切换到 G2 继续执行,G0起到调度的作用。
# 3.2.2 全局队列获取空闲 G
如果本地队列没有空闲的 G,那么就会去全局队列偷取 G 来运行,偷取数量参考如下公式:
n = min(len(GQ) / GOMAXPROCS + 1, cap(LQ) / 2 )
# 3.2.3 全局队列也没有空闲的 G
如果全局队列也没有空闲的 G,就去其他队列偷取一般的 G 过来运行。
# 3.2.4 没有空闲的 G
如果都没有空闲的 G 了,那么 M 就处于自旋状态,不断尝试获取空闲的 G。因为 M 的创建、销毁也会损耗系统资源,但是只有绑定了 P 的 M 才能保持自旋状态,就是最多只能 GOMAXPROCS 个 M 自旋。
# 3.2.4 网络轮旋
看教程时,看到有评论说 P 获取 G 的顺序为:本地队列 -> 全局队列 -> 网络轮询 -> 其它 P 队列偷取。
网络轮询,后面再深入了解吧。

# 3.3 系统调用(syscall)
如果 G1 进行了系统调用,无论阻塞还是非阻塞,都会导致当前绑定的 P 与 M 解绑,然后 P 绑定到新的 M 上面,当 G1 执行完后放入全局队列,M 休眠。